
Extracting rational thoughts from behaviour
12 August 2021
An interview with Dr Xaq Pitkow, Baylor College of Medicine and Rice University, conducted by April Cashin-Garbutt
How do we measure a thought? In traditional neuroscience, researchers measure brain activity and relate it to something in the outside world such as a sensory stimulus or muscle movement. Yet in cognitive neuroscience, researchers aim to relate neural activity to thoughts, which are notoriously difficult to measure. To try to accomplish this, Dr Xaq Pitkow has developed a scientific tool called Inverse Rational Control (IRC). In his recent SWC Seminar, Dr Pitkow outlined how he uses this new method to learn an agent’s internal model and reward function by maximising the likelihood of its measured sensory observations and actions. In the following Q&A, Dr Pitkow explains how IRC thereby extracts rational and interpretable thoughts of the agent from its behaviour.
Animals' thoughts about natural tasks are implemented by activity patterns in the brain. These patterns can be described by abstract, dynamic mathematical relationships that can be inferred using Inverse Rational Control.
Why is it challenging for neuroscientists to use behaviour and neural activity to understand internal models?
There is so much that we can’t see, and even when we can, the patterns are so complicated that we don’t know how they relate. Essentially it is a problem of high dimensionality. When you have a huge number of variables in a high dimensional space and only some of which matter, it is easy to get fooled about which ones are relevant.
Both humans and algorithms pick up on spurious correlations and this causes a problem called overfitting. Overfitting is where it looks like a certain pattern is related to an outcome, but it is actually caused by another pattern. Superstitions, like fear of Friday the 13th, can be an example of this.
This is a huge problem when studying how the brain engages with the world. If you have a sufficiently powerful neural network, it can learn any function. But that doesn’t necessarily mean that all functions are equally easy to learn, nor that this powerful network picks up the right kinds of patterns. If you don’t impose some structure, then you’re subject to overfitting unless you have an enormous amount of data (which we don’t have). As a consequence, humans need to build-in, and artificial networks need to be given, some intrinsic biases to favour the right kinds of structure for our world.
There are some theorems about this, such as the “no free lunch” theorem, which says that you can’t have a universally good optimisation that works in all conditions. You need to be tuned for a particular world if you want to do well in that world. Another theorem is called the “good regulator” theorem, which says that anything that is going to control a system has to be a good model of that system.
The problem is, we don’t know what those intrinsic biases are that the brain uses to interpret its world well. Because we don’t know them, all of these possible patterns are possible explanations. As we learn more, we can start to focus on looking at certain patterns that are more likely to be responsible for the actions that we see in behaviour. What we’re trying to explore are the fundamental principles that give us guidance about where to look.
How do you define rational behaviour? Can we assume agents behave rationally?
No, we cannot assume that agents behave rationally, but we often do! The way I like to define rational is optimal but for the wrong model. For example, if you carried out a certain behaviour that doesn’t have a clear explanation, you might give it a justification post hoc. This justification of what you did might not be the real reason or even a good reason, but it might be a good reason if your wrong assumptions were true. In the same way, by rational I mean optimal with the wrong justification.
Under what circumstances are agents less rational or irrational and how is this captured in your model?
Our notion of rational is fundamentally tied to the notion of justification, so if we don’t have a reason then by definition something is irrational. However, it could be just that we didn’t find the right reason. In neuroscience, researchers have traditionally carried out experimental tasks that are very unnatural for animals compared with what they experience in the wild. Under these unnatural experimental conditions, an animal’s behaviour might seem irrational, but their actions would actually be a perfectly good thing to do if they were living in the wild.
Nowadays we push for experiments to be more natural where we can. However, making a model of the wild is incredibly hard. It could be that all of the irrationalities that we observe can be explained as rational under the right assumptions, but we need to push hard to find those assumptions. It might be that there’s a good mental model that explains it, or it might be that it’s the rational thing to do when you only have 100 neurons in your brain and it’s the constraint on the neurons that creates limitation as opposed to the world itself. Thus we have different sources of apparent irrationality and once we account for those constraints or bounds, then we might be able to explain things as rational again.
One prominent alternative unprincipled model is that the brain is just a big bag of tricks. Even if this were the case, you could still ask why this particular bag of tricks and how does the brain select which trick. For example, did these tricks prove evolutionarily to be useful? We know that a lot of animals are hard-wired for certain behaviours from birth, whereas other animals do a lot of learning.
If you take an animal that mostly behaves the same way from birth, you’ll have one class of models of rationality that doesn’t include learning because learning is not part of that animal’s way of being in the world. Whereas, if you have an animal that learns, you now have to make a model of why it is rational to learn in a particular way. It might be that this is the globally optimal way to do things (which is highly unlikely), or it could be constrained by the machinery that the animal is able to learn with. Neurons are connected by synapses and the synapses are changeable, but they typically only receive local information, so that is a bound on what they’re able to do. Even if the neurons would perform better if they used non-local information, they are not physically capable of doing this, so you get bounded rationality or computationally-constrained action.
Can you explain the new method you applied, Inverse Rational Control (IRC), to learn an agent’s internal model and reward function?
Imagine that you can solve any task that you want – each one of those tasks would give you a different strategy, for example ‘if you see this, then you should do that’. This mapping from what you’ve seen to what you do, is what we call the ‘policy’. Policies will differ for different tasks. So, for example, you should behave differently if you think your environment is very volatile versus very steady.
In IRC, we take an entire family of artificial agents, each following a policy that is optimal for a different world, and we challenge them with the same single task that we gave to the animal. We then ask which one best matches what the animal did? We say that the animal assumes the world behaves like the world in which its policy was optimal. We can also figure out how valuable the rewards are to the animal, and how costly its actions are, because these affect when and how the agents acts. We say that the animal’s preferences are the same as those of the agent that behaves the same way.
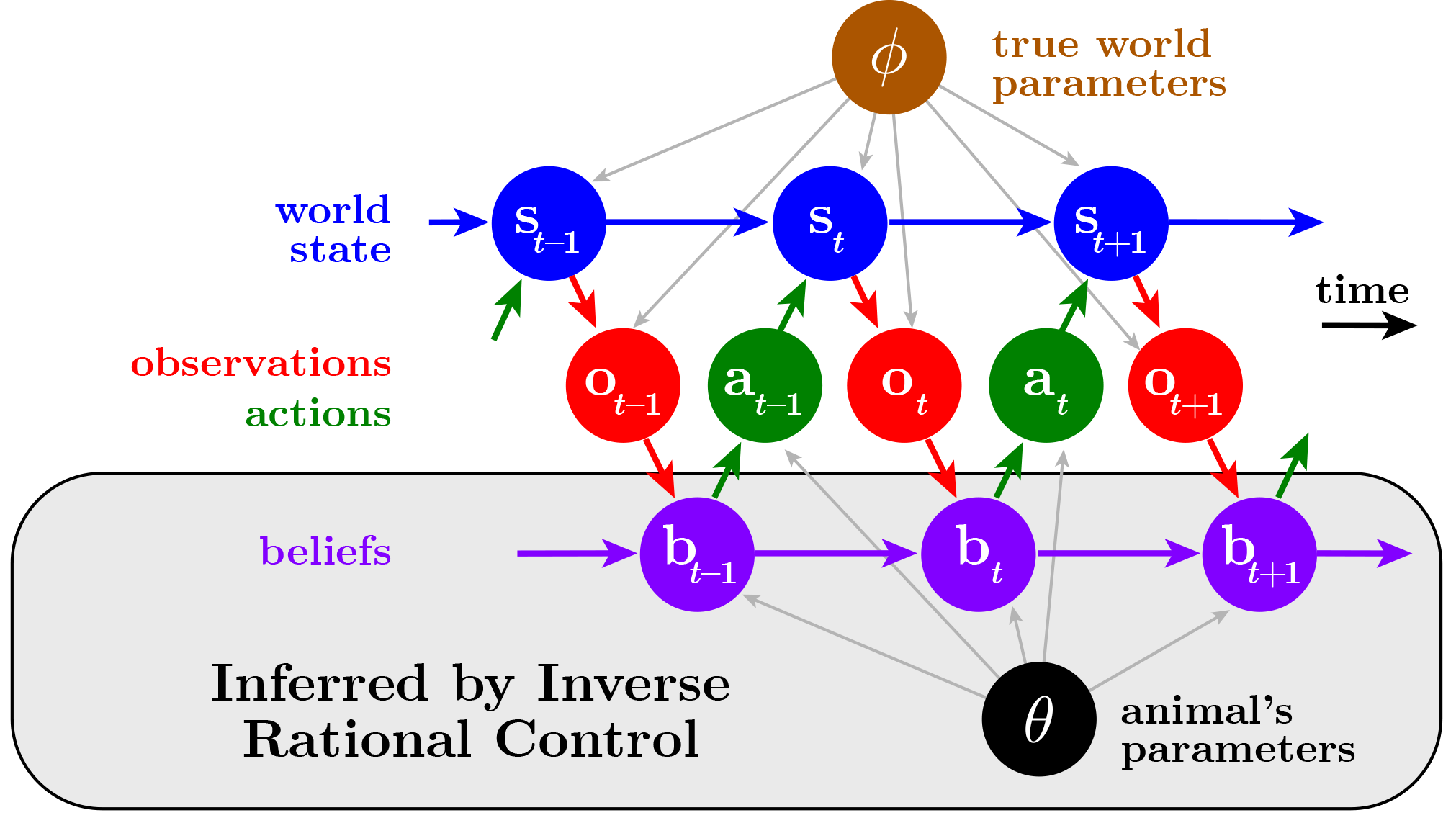
We model tasks and the animal's assumptions by graphs, where each circle represents a variable and each edge reflects how those variables interact causally. For our task model, we assume that the world is described by a state (blue) that evolves according to some rules (brown). The world gives the animal some imperfect sensory observations (red), leading the animal to construct a belief about what the world state might be (purple), depending on its assumptions about how the world works (black). This in turn leads the animal to choose actions (green) that are rational — that is, achieve the best outcomes according to the animal's possibly mistaken assumptions. Inverse Rational Control uses the behaviour to infer the animal's beliefs and assumptions (grey).
How does IRC extract rational and interpretable thoughts of the agent from its behaviour?
Once you have an agent that is optimal on some task, then you can ask what is this agent thinking at any time. We can’t do this with the animal directly, as we don’t know what the animal is solving. But now with IRC we can know a lot more about the rational agent that best matched the animal. For example, we know the agent’s mental parameters — the rules it thinks govern the world — which we couldn’t know for the animal. So we can now assign those mental parameters to the animal.
Part of the animal’s actions are driven by a belief about the world, and by determining the belief of the agent we can then attribute that belief to the animal. This allows us to make hypotheses about what should be happening in the brain, by understanding what information is motivating the animal to do these things.
When you look in the brain, you then need a second level of hypotheses about how that belief gets represented by neural activity – we call that a linking hypothesis. This is another complicated problem as it could be represented in many different ways such as probability, log probability, samples and so forth.
Do you think IRC would also work in humans?
Yes, we are currently doing this with worms, mice, monkeys and humans. The conceptual framework is the innovation but then you can apply it to lots of different animals using different tasks.

The lead author of this work, Zhengwei Wu, solved a difficult mathematical puzzle.
Are you seeing many differences across different animals?
We are not far enough along to be able to answer that question. We are interested in looking at the same task in different animals, but right now we have different tasks in different animals. We do expect there will be strong and profound differences in the way that a monkey or a human thinks about the world compared to a mouse or a worm. We expect that the representations will be more sophisticated in primates as they may have a richer internal model. They may also be biased in certain ways that mean they might not be as good at the experiment. There are cases where animals outperform humans at experiments and this may be because, as humans, we are assuming a more complex world, whereas the animals are rationally assuming a world that is closer to the experiment.
What is the next piece of the puzzle your research is going to focus on?
We’re very interested in generating hypotheses about beliefs about latent variables in the brain, so that we can look for them. This is our next big endeavour and we’re collaborating with lots of people to try this out and we have made some good progress but we have a lot further to go.
Another area we’re interested in is to look at what constraints we can put on the internal representations that would explain the behaviour. Right now, we’re assuming that, given the observations and a model of the task, the animal is doing as well as it is possible to do. But the constraints are very powerful for the animal. We want to look at how we can add constraints that structure our knowledge, and actually lose information in a useful way. How do we impose that on these models? This is the domain of simultaneous reinforcement learning and representation learning. Once we do that, how do we interpret those learned representations? We’ve lost some of the interpretability by gaining some more biological realism and flexibility, so we have to do some extra work to relate those new ideas.
About Dr Xaq Pitkow
Xaq Pitkow is a computational neuroscientist aiming to explain brain function by constructing quantitative theories of how distributed nonlinear neural computation implements principles of statistical reasoning to guide action. Although he is a theorist, he at one point did perform neuroscience experiments, and still collaborates closely with experimentalists to ground his theories, help design experiments, and analyse data. He was trained in physics as an undergraduate student at Princeton, and went on to study biophysics for his Ph.D. at Harvard. He then took postdoctoral positions in the Center for Theoretical Neuroscience at Columbia and in the department of Brain and Cognitive Sciences at the University of Rochester. In 2013 he moved to Houston to become a faculty member at the Baylor College of Medicine in the department of Neuroscience, with a joint appointment at Rice University in the Department of Electrical and Computer Engineering. He has been a professional graphic artist since he was 12, and enjoys sculpting and digital art, which he often integrates into his scientific work. He also enjoys improvisation on piano, tabla, and two dozen other musical instruments.


