
Teaching artificial networks how animals pose
26 February 2024
An interview with Dr Matthew Whiteway, Columbia University, conducted by Hyewon Kim
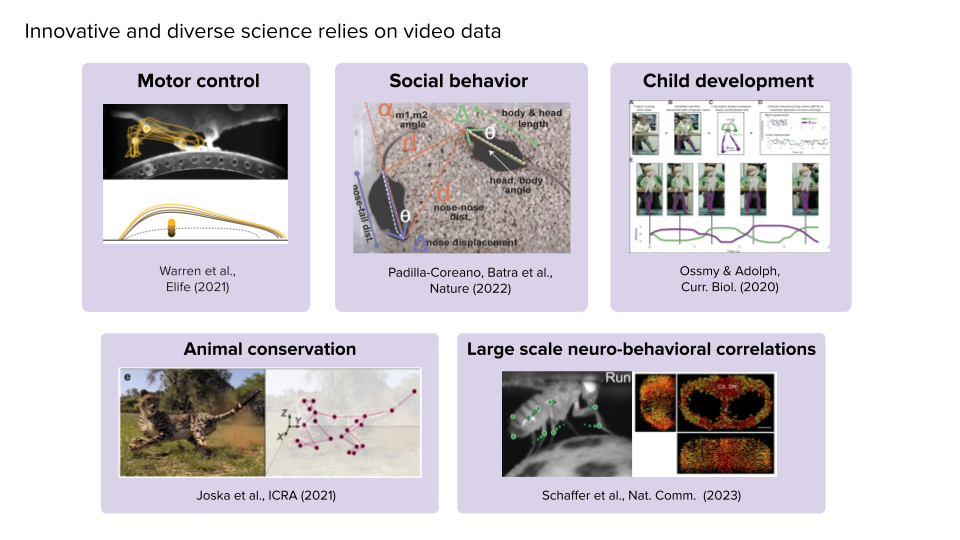
The current landscape of pose estimation algorithms in neuroscience is driven by the need to extract robust and reliable predictions of animal movement over time from video data. These algorithms play a crucial role in unravelling the intricacies of sensory processing, decision-making, and adaptive behaviour in animals.
In this Q&A with SWC Seminar speaker Dr Matthew Whiteway, we delve into the nuances of pose estimation, contrasting supervised and unsupervised approaches, discussing the novel aspects of the Lightning Pose algorithm, and exploring its potential impact on neuroscience research.
What is the goal of current pose estimation algorithms?
The goal is to extract over time robust and reliable predictions of where different key points on an animal are in a video. Generally in neuroscience, there are a lot of different questions you can ask about sensory processing, decision making, navigation, etc. A lot of these questions also involve the behaviour of the animal. An animal is constantly exploring its environment and responding adaptively to cues in the environment. It's not just sitting passively and experiencing things.
Why do neuroscientists want to estimate the poses of animals and how have they achieved pose estimation in the past?
In order to really understand the neural circuits we're recording from, we also have to understand the behaviour of the animal. Previously, people have recorded behaviour in somewhat easier ways. For example, in decision making experiments, you might care about whether the mouse thinks the stimulus is on the right or the left and have the animal lick to one side or the other. That’s a fairly simple description of the behaviour. And even though that's ultimately what you're interested in, it misses all the other things the mouse is doing, like moving its whiskers or grooming itself in the middle of the task. All of these things matter and are reflected in the neural activity. So you really need to know the behaviour in order to understand what's going on in the neural activity.
There are different ways of recording rich descriptions of behaviour, but video cameras are very simple and relatively cheap. It's a very general way to capture what the animal is doing. You can collect a lot of video data, but then you need algorithms that can extract more information from that video data.
Pose estimation has emerged as one of those processing techniques that is very helpful for people. In the past, there have existed other ways of extracting similar sorts of information. Very early on, it was traditional computer vision methods that tracked the centre of an animal as it moved through a maze or walked around in an open field. But as time has gone on and computer vision advanced, and deep learning came into the picture, we can do more sophisticated things like track specific points on an animal over time.
What is the difference between supervised and unsupervised approaches?
In the very broad sense, supervised methods require the data you're analysing and a set of human-defined labels for pose estimation. ‘This is where this body part exists in this frame.’ People are also interested in behavioural segmentation where you tell the algorithm, ‘In this group of frames, the animal is grooming and in this group of frames, the animal is sitting still.’ But all the labelling is done by humans. The benefit to that approach is you know exactly what you're getting – what is going into the algorithm what is supposed to come out of it.
On the unsupervised side, the user of the algorithm doesn’t want to make any strong statements about what they’re looking for. They just want to find repeatable patterns in the data. And that can be more powerful in some sense because it's unbiased – it doesn't rely on the experimenters defining what is important. There could actually be something else more important going on in the data that the user doesn't know about. The often-claimed advantage to unsupervised methods is precisely that they're unbiased. And the user doesn't have to label data so they can usually train the algorithm with a lot more data. The downside is that the user is never really sure what they’re going to get out of the algorithm. It could output some results, but it may be hard to interpret that as a human.
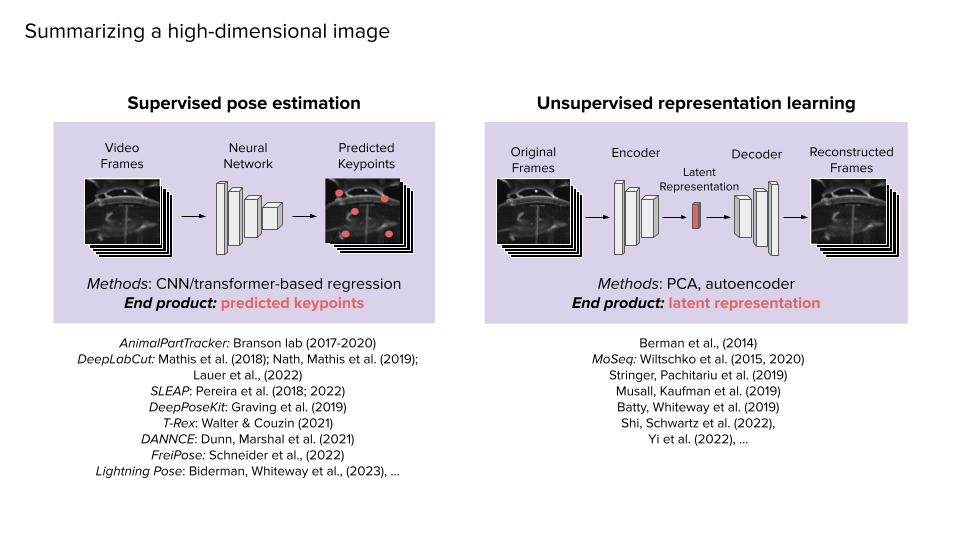
So, there's a tension between unsupervised and supervised methods. Do you want something that takes more work upfront, but that you can understand what it's giving you? Or do you want to train the algorithm with a lot more data, but are okay with not exactly knowing what its results are? It depends on what your scientific question is and what the downstream analyses are.
What was the problem or set of limitations your team tried to tackle as you were developing your Lightning Pose algorithm?
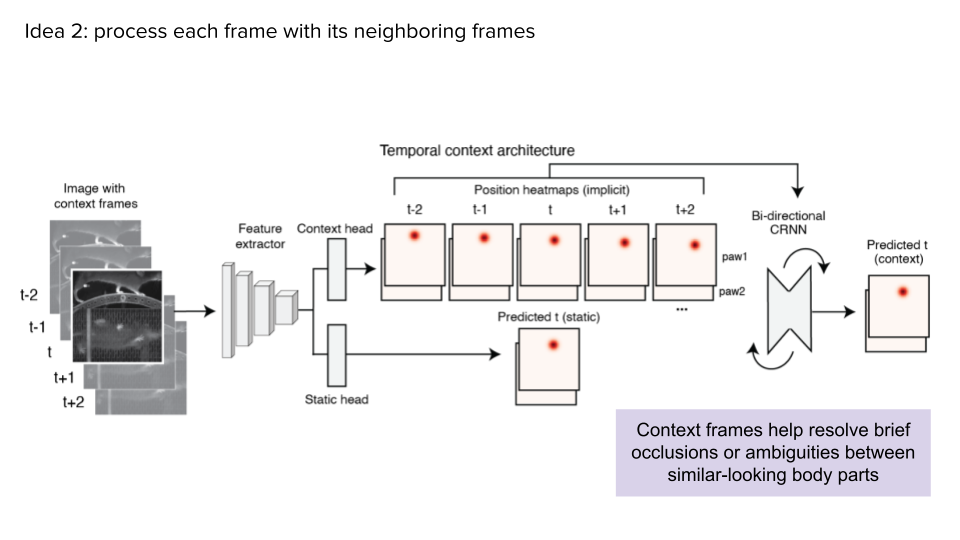
When we started working on this project, there were already many people using existing pose estimation tools, which worked well most of the time. They didn't work maybe 1% of the time. That might sound like a relatively small percentage – they were doing what they were supposed to do 99% of the time. But oftentimes it's during that 1% when interesting things are happening and might be of scientific interest!
For example, if we have an experiment where two mice are running around and interacting with each other, existing tools might do just fine tracking the mice when they're separated. And it's when they're starting to interact and one is in front of the other, or they're touching each other in some way, that's the 1% of the time when there are issues. But that's actually the scientifically interesting part of the experiment. So that was the problem we saw – existing tools aren't 100% perfect and when they are wrong, it's usually in times when we really want them to be correct.
We would work with a lot of collaborators and experimental labs who would come to us and ask how existing algorithms could be improved. And our answer was always to label more data – the more labelled data there are, the better the tools will perform. But that can only be a satisfying answer for so long and eventually we wished there was a way we could improve the algorithm’s performance without telling people to just label more data.
If you're not going to label data, how else are you going to make the algorithm perform better? There are a lot of different answers to that question. We could improve the models and improve the loss functions.
But what we wanted to try was to train the models with more data that didn't have associated labels. The name of the game became: How can we throw a bunch of unlabelled data into these algorithms and use them to improve the outputs of these models? That is what we’ve been spending a lot of time focusing on.
How would you explain the architecture of your network to those unfamiliar with the structure of these models?
We use a convolutional neural network. Imagine what we want to do is to extract certain features from a 2D image that we feed into the network. The question is, how do you extract meaningful features from this dataset of pixels that will allow you to localise the body parts of an animal? One way to think about a convolutional neural network is to compare its set of filters to those in Adobe Photoshop. Maybe you have a filter that highlights vertical edges.
You can imagine running that filter over your entire image and then you have a kind of feature map that tells you where the vertical edges are in the image. And you can do that with another filter that maybe finds horizontal edges. Then you can do that with another one that finds 45-degree edges. You can then do this in more complicated ways where you're not just finding edges, but certain types of curves.
You eventually build up a whole library of filters that you can apply at once to your image. You then have a new representation of your image. With these convolutional neural networks, you repeat this process over and over. You apply all these filters, get feature maps, then you apply another set of filters followed by another set of filters on another set of filters.
But because this is a neural network, you don't actually say what these filters should be. You're not the one setting up the vertical line or horizontal line detector. You let the model learn what’s useful from the data on its own.
You randomly initialize some filters and let the networks learn from the data what these filters should be. In the end, you get a feature representation of the image you've put in. This feature representation might be hard to understand and that's why these networks are often called black boxes. You don't really know what's being picked up. But the important thing is that you can use those features to then predict the coordinates of different key points that you care about. The neural network will learn on its own what those features should be, so it makes that task as easy as possible.
At the end of the day, you put an image into this neural network and all these filtering operations happen over and over again. And you eventually get an XY coordinate for each body part of the animal. That's where the network thinks where the nose is, where the ear is, and where the other ear is. That's what you take and go do further analysis with.
In light of what you just described, would you say the semi-supervised aspect of the Lightning Pose algorithm is what is novel to the field?
Definitely. Before, it was always a supervised approach where you put in the image and then checked that it matched the ground truth labels. That's how you trained these networks – by doing this over and over again. ‘Here's the image, here's what the answer should be.’ On repeat.

The semi-supervised approach we're taking means you can now put in unlabelled video data and you get out all of the XY coordinate predictions. But you don't have any hand labels or ground truth annotations. That’s the novelty of Lightning Pose, defining some way of determining whether or not these predictions are good. If they're good, we leave them alone and if they're not, we try to make them less bad. The tricky part is determining what is good and what is bad. You don't actually know what the ground truth answer is.
Could you also share about the post-processing that improves tracking accuracy?
Sure. Whenever you get the output of these networks, you get the X and Y coordinates in the image and you also get a confidence value that goes between 0 and 1. Zero means the network is not at all confident about its answer. 1 means it's very confident about its answer. People typically select some threshold and say that if the confidence is below 0.9, then the coordinate is probably a bad point. You can then drop all of the bad points and try to figure out some way to fill in the missing data.
The problem is that the confidence value you get from the network is not something that I trust. If it's really low, I would trust that it probably is a bad prediction. But if it's high, it could be good or it could be bad. A lot of existing post-processing techniques rely on using that confidence to know which points need fixing and which points are fine.
Our solution is, instead of just fitting a single network, to fit a bunch of different networks – maybe five. You can play little tricks to make sure they give you different answers. You can train them on different parts of the data, or initialize some of the weights differently. So even if you train them the exact same way, you're going to get slightly different answers. The idea is that if all of your networks give you basically the same answer, then it's likely that is the correct answer. If they all give you a bunch of different answers and the variability across those predictions is large, then surely some of them are incorrect. So, we can flag these key points and say there's an issue there. That's how we get around this issue of confidence not being a good measure of whether the points are good.
Once we have that, we then fit a model called the ensemble Kalman filter or ensemble Kalman smoother. There are two components of the model. The first is the observations along with some measure of how much you trust that observation. Those are the ensemble variance. The second piece is some model of how the behaviour, or key point, should look as it evolves in time. This model is based on unsupervised losses that we define.
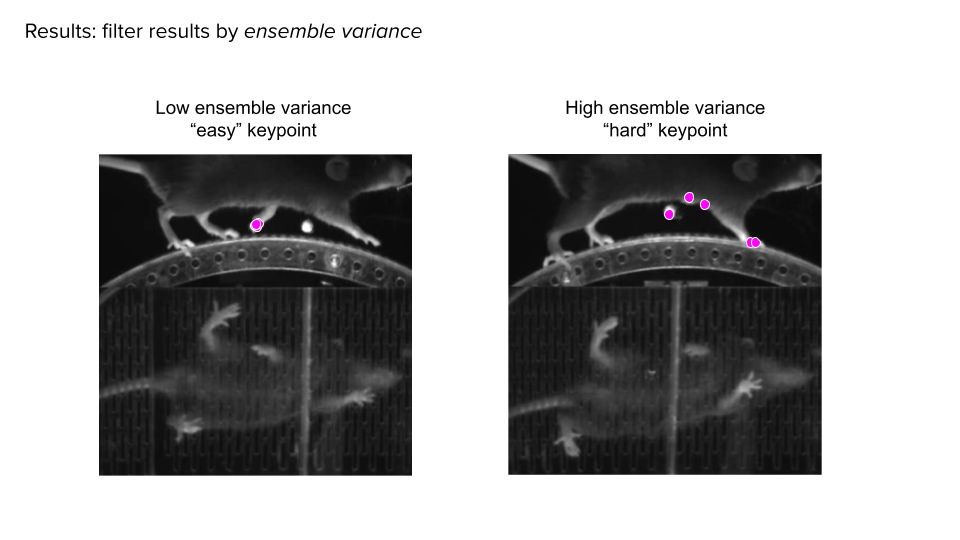
The model incorporates the idea that key points should change smoothly over time and that there's a particular geometry that aligns with predictions across multiple views. It also accounts for the low dimensionality of the pose, filtering out implausible configurations.
Combining these concepts, we use the model to predict the next point given the current prediction. If observations are consistent and ensemble variance is low, we rely on the average value. Conversely, when ensemble variance is high, we defer to the model's output. This process involves weighting and combining both model and observation outputs, adjusting the balance based on ensemble variance, sometimes evenly split or skewed towards one or the other.
Were you at all surprised by how well your Lightning Pose algorithm performed?
I'm happy with it now, but it took a long time to reach this point. We had these conceptual ideas a while back, but it was a gradual process to successfully implement them. We experimented with different approaches. Some worked while others didn't, requiring tweaks along the way. From the initial implementation to its current state, there's been about a year or more of refinement. Progress was gradual, but we steadily improved the system.
I would say at no point was I surprised – I was almost surprised it didn’t work very well in the beginning. But over time, we brought it closer to our expectations. Now I'm pleased with the outcome, which aligns with our original hopes. Having tested the algorithm primarily on one dataset, it's satisfying to see its effectiveness across various datasets. We've applied it to mice, fish, and flies, with plans to expand to other species in the future.
How do you envision Lightning Pose being used by neuroscientists going forward?
I hope for two main uses of our tool. Firstly, I aim to simplify its use for neuroscientists. Deep learning models can be complex to set up and fine-tune, requiring specific hardware and expertise. So my goal is to provide a user-friendly tool, minimising the time researchers spend on installation and parameter adjustments. This way, they can focus more on their scientific inquiries rather than technicalities. I would love to see the tool used in a variety of model organisms and for various scientific questions because it's a very general algorithm. That would make me happiest – seeing a wide variety of uses for it.
Secondly, I want to foster experimentation and innovation in pose estimation. Our software is designed to facilitate the exploration of new ideas in this field. These loss functions that we use are by no means the best or set in stone. I encourage machine learning experts and data analysts to leverage our platform for testing alternative approaches and techniques. By collaborating in this way, we can advance the capabilities of pose estimation and broaden its applications across diverse scientific domains.
How would you say your career trajectory so far has informed what you do now?
I started with physics as my major in undergrad. Initially, topics like projectile motion and electromagnetism were intriguing. But as we delved deeper into atomic and nuclear physics, which are far removed from our daily experiences, I found them less captivating intellectually. Upon entering grad school, I pursued an applied math program. While I enjoyed math, I sought to apply it to questions beyond physics.
This led me to a computational neuroscience lab during my grad school years, where discussions revolved around sensory processing and decision making, topics more relevant to everyday life. Transitioning to my postdoc, I became more involved in behavioural video analysis, finding it even more relevant. While neural activity occurs within our heads constantly, it's challenging to understand it directly. However, observing videos of animals, such as mice exploring their environment, resonates with experiences we can easily relate to, like watching my dog roam around the backyard. I gravitated towards studying phenomena I could observe in the world around me, which has been my primary motivation.
What would you say are some of the next projects you're excited about?
I've been initially interested in pose estimation, but more so in what follows pose estimation. Once you have the general pose of the animal over time, you can start asking interesting questions like how it correlates with neural activity or how the brain implements behaviour. It opens avenues for fitting models of behaviour, understanding transitions between behaviours, and studying interactions among multiple animals.
However, all of this relies on accurate pose estimation or effective ways of extracting information from videos. Moving forward, I'm excited to delve into answering scientific questions enabled by better pose estimates across various species through multiple projects.

About Dr Matthew Whiteway
Matt Whiteway is an Associate Research Scientist at the Zuckerman Institute (Columbia University) and a Data Scientist at the International Brain Lab. His research focuses on developing open source tools for analysing large-scale neural and behavioural datasets. This research builds on his work as a postdoctoral researcher in the Paninski Lab at Columbia University.

