Making data sharing easier for neuroscience
23 March 2023
By Hyewon Kim
“We do it based on trust,” remarked Satra Ghosh during the discussion session on the first day of NeuroDataShare 2023. The two-day main meeting preceded another two-day hackathon, both hosted at SWC last month, and centred around collectively addressing the challenge of how neuroscience data can be structured to facilitate reuse. Organised by Angus Silver, Padraig Gleeson, and Isaac Bianco, the meeting brought together multiple perspectives ranging from science that’s already employing open data sharing procedures, needs that have been met versus unmet, to what funders are supporting and looking for, as well as suggestions for a standardised file naming structure.
At the core of these discussions lay a desire for implementing trust into agreed-upon standards. With the precipitous rise of large-volume neural data collected from advanced imaging and electrophysiology techniques, it was clear to all that the “passing on [of] the knowledge” as phrased by kick-off speaker Mei Zhen is “not just about the data itself”. In order to make sense of the large-scale data from multiple biological scales ranging from the synapse to brain regions, the community needed to discuss and eventually adopt new ways to make data sharing, and in turn data understanding, easier.
Neurodata structuring in practice
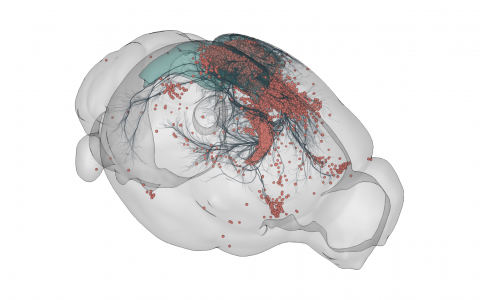
Neuroscientists from institutions in Germany, the UK, India, Canada, and the US shared examples of and lessons learned from their own applications of a data structuring and open sharing policy. From a “queryable” virtual fly brain as presented by David Osumi-Sutherland and single neurons modelled by Upi Bhalla, to a map of the murine brain vascular connectome by David Kleinfeld and the discovery of lower visual coding precision in food-restricted mice by Nathalie Rochefort, the need for a data sharing system not only to help external groups regenerate figures using the same data but also to reuse it for novel analyses was deeply felt.

Nathalie Rochefort explains how her team found that food restriction in mice leads to lower visual coding precision.
Carles Bosch Pinol emphasised the need to “bridge across [biological] scales” by employing multimodal imaging techniques in his study of the mouse olfactory bulb synaptic circuit. We need to pay attention to data infrastructure for multi-user annotation of datasets to be possible. Moritz Helmstaedter, in his group’s quest to incorporate the time element into the connectome, highlighted how imaging data is dramatically increasing into the order of petabytes as studies of the entire cortical column using multi-beam electron microscopes take place.
Acknowledging the unique requirements of neuroscience
Speakers seasoned in their experience with neurodata structuring and accessibility also contributed to the discussion. Oliver Rübel of NeuroData Without Borders suggested that what is needed are not just rigid standards, but a new language. He argued for a “data standard ecosystem” to overcome the challenge of diverse stakeholders as well as diverse experiments in the face of rapid technological innovation.
SWC Head Research Engineer Adam Tyson shared his experience developing the BrainGlobe Initiative, stressing that facilitating data sharing at each stage is important. “Neuroscience has unique requirements,” he concluded, addressing some of the limitations of pre-existing tools. Padraig Gleeson focused his talk on the importance of computing infrastructure, highlighting the loop between experimental neuroscience and computational neuroscience. “Computing infrastructure should be informed by databases and open simulation tools,” he said.
Concrete suggestions for meeting existing needs were welcome, and perspectives were shared by neuroscientists reflecting on their own experiences while also looking ahead to the next generation. Satra Ghosh of the DANDI platform suggested starting with university students, who could be given problem sets on optimal data structuring, while Ken Harris put forth an idea for an open neurophysiology naming standard for datafiles. “Ease of use is key,” he stressed. Andreas Tolias recounted his own experience sharing functional connectomics data (MICrONS) with the global community and running a workshop at the NeurIPS conference.

Andreas Tolias shares his research on how the brain can generalise.
Encouragement from funders to level the playing field
Funders also added their takes to the conversation. Stephanie Albin of the Kavli Foundation shared the foundation’s approach to finding solutions, supporting projects to share and standardise data and creating new opportunities for open data. Such opportunities included the NeuroData Without Borders Seed Grant, a recipient of which commented: “Not everyone is equally computer savvy, but everyone generates data files. There needs to be an interface that acknowledges the diversity of expertise.”
Hannah Hope of Wellcome asked the audience, how can funders contribute to an ecosystem of transparency in research? “Can you yourselves be the enforcer,” she suggested. “Funders value what they see,” she continued. “Be bold in citing peer reviews that you conduct. Let’s reimagine how we talk about research, questioning the current peer review system and championing alternative systems.”
Tackling barriers to sharing and reusing data
Both meeting days ended with a discussion session, during which speakers and the audience came together to brainstorm solutions to the challenges presented. Some emerging themes included what the incentives would be for sharing data, especially for small labs, as well as how the field can foster a culture of data reuse. The latter had been emphasised by Saskia de Vries in her talk about the Allen Brain Observatory’s examples of how large datasets, when reused, enabled novel discoveries. “You are biggest reuser of your own data,” she pointed out.

Each day of the meeting ended with a discussion session involving both speakers and members of the audience, addressing questions like: What are the main barriers to reusing data?
Martin Haesemeyer added to the discussion about currently unmet needs, including how good behaviour can actually be enforced. He questioned the usefulness of automated analysis, pointing out that his lab, which studies how larval zebrafish thermoregulate, usually uses custom codes and data structures. This brought to attention the amount of time that would be required for a lab to adopt a new file standard.
While the meeting focused more on hashing out what works and what doesn’t than honing in a single solution, the forum for discussion around what would make data sharing easier was widely appreciated. The discussion session at the end of the second day of the main meeting asked both speakers and the audience: How well do data sharing initiatives work? How should the costs be met? Do we need new tools/resources? How should people be trained? How can we increase uptake? What does data sharing mean for small independent labs versus large programmes?
Building trust into a standardised data sharing system meant that such conversations, no matter how inconclusive or aspirational, needed to be had. ‘Incentive’ was a keyword of the two-day discussion, given the time and cost that would go into adopting a new data standard especially by smaller labs and those that customise their own data structuring. Improving the data standard ecosystem called for trustworthy motivations that would stem from a reliable transition from data to knowledge about the brain, and harnessing the feeling of overwhelm in the face of a data deluge and transforming it into collective action.